 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
LMM基础知识
选择下⼀个词:
GPT是寻找在某种程度上意义匹配的事物。
最终的结果是,它会列出随后可能出现的词及其出现的概率(按概率从高到低排列)。
有了这个带有概率的词列表,我们就会从这些词中选择一个词。
- 接下来再把这个词附加到我们的文本上,再次询问大模型下一个词是什么。
本质上,我们生成的一段内容就是这样一遍一遍地询问下一个词是什么,不断地重复这个过程。
引入随机性:
如果我们总是选择排名最高的词,通常会得到一篇非常平淡的文章,完全显示不出任何创造力。
- 这就好比你问别人一个问题,他每次都给你同样的回答,你一定会觉得这个人非常的无趣。
所以,在选择的时候,我们可以有一些随机性,选择排名较低的词,这样我们就可以得到一篇更有趣的文章。
温度(Temperature):
在 OpenAI 的 API 中,这个参数越小,表示确定性越强,越大,表示随机性越强。
有了温度之后,对于同样的提示词,就产生了不同的结果。
从字符串到向量:
字符串只是这些 AI 算法的一种输入,还可以输入图片、输入视频,甚至各种各样的信息。
- 只要把这些输入都转换成向量,AI 算法都可以轻松地驾驭。
交给 AI 算法处理的前提就是把各种信息转换成向量。
字符串是怎样变成向量的?
在大模型的处理过程中,字符串转成向量会经历两个步骤:
- 第一步叫 One-Hot 编码。
- 第二步则是把编码的结果进行压缩。
One-Hot 编码就是将离散的分类值转换为二进制向量。
比如,有一个颜色的分类值,分别是红(red)、绿(green)、蓝(blue),其编码如下所示:
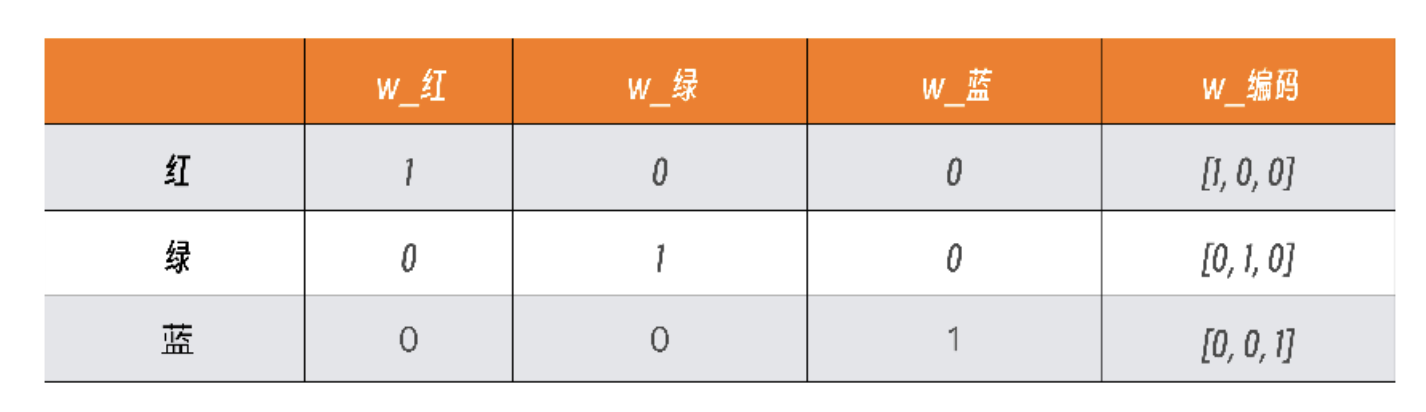
在这个表格中,可以看到红绿蓝在向量里各占一位,有值则为1,没有值对应0。
- 所以,红对应的向量是[1,0,0]、绿对应的是[0,1,0],而蓝对应的是[0,0,1]。
当我们输入是红绿红蓝,就会得到对应的四个向量:[1,0,0]、[0,1,0]、[1,0,0]、[0,0,1]。
这就是最简单的One-Hot编码。
离散的值是什么?
把字符串转成Token列表,每个Token都会自己对应的一个唯一标识,而这个标识就是向量中的内容。
获取 Embedding常用的方法有两种:
降维和把 Embedding训练成神经网络。
- 降维的技术有很多,比如主成分分析(PrincipalComponentAnalysis)。
但在大模型中,通常使用把 Embedding训练成神经网络的方法。
- 也就是把我们前一步得到的向量送给一个神经网络,得到最终的压缩过的向量。
经过这个处理之后,一个硕大的向量就会压缩成一个固定大小的向量。
比如,在GPT3中,每个Token都由768个数字组成的向量表示。
- 之后,再把压缩过的向量作为输入传给大模型,用来生成最终的结果。
提示词:怎样与大模型沟通
站在用户的视⻆,写好提示词只需要掌握一个提示词公式即可,这个公式就是:
提示词=定义⻆色+背景信息+任务目标+输出要求。

零样本提示(Zero-Shot Prompting)
大模型的一个特点是知识丰富,所以,大模型本身是知道很多东⻄的。
我们就可以利用这个特点,让它帮我们做一些通用的事情。
- 在这种情况下,我们不需要给大模型过多的信息提示。
这种提示词的写法称为零样本提示(Zero-Shot Prompting)。
少样本提示(Few-Shot Prompting)
虽然大模型知识丰富,但它并不是无所不知的,尤其是它对我们要完成的工作甚至是一无所知的。
这时,我们只要给它一些例子,帮助它理解我们的工作内容,它就能很好地进行推理。
少样本学习在简单分类的场景是很好用的,但它也有很强的局限性。
比如,在一些复杂的推理任务中,它就显得力不从心了。
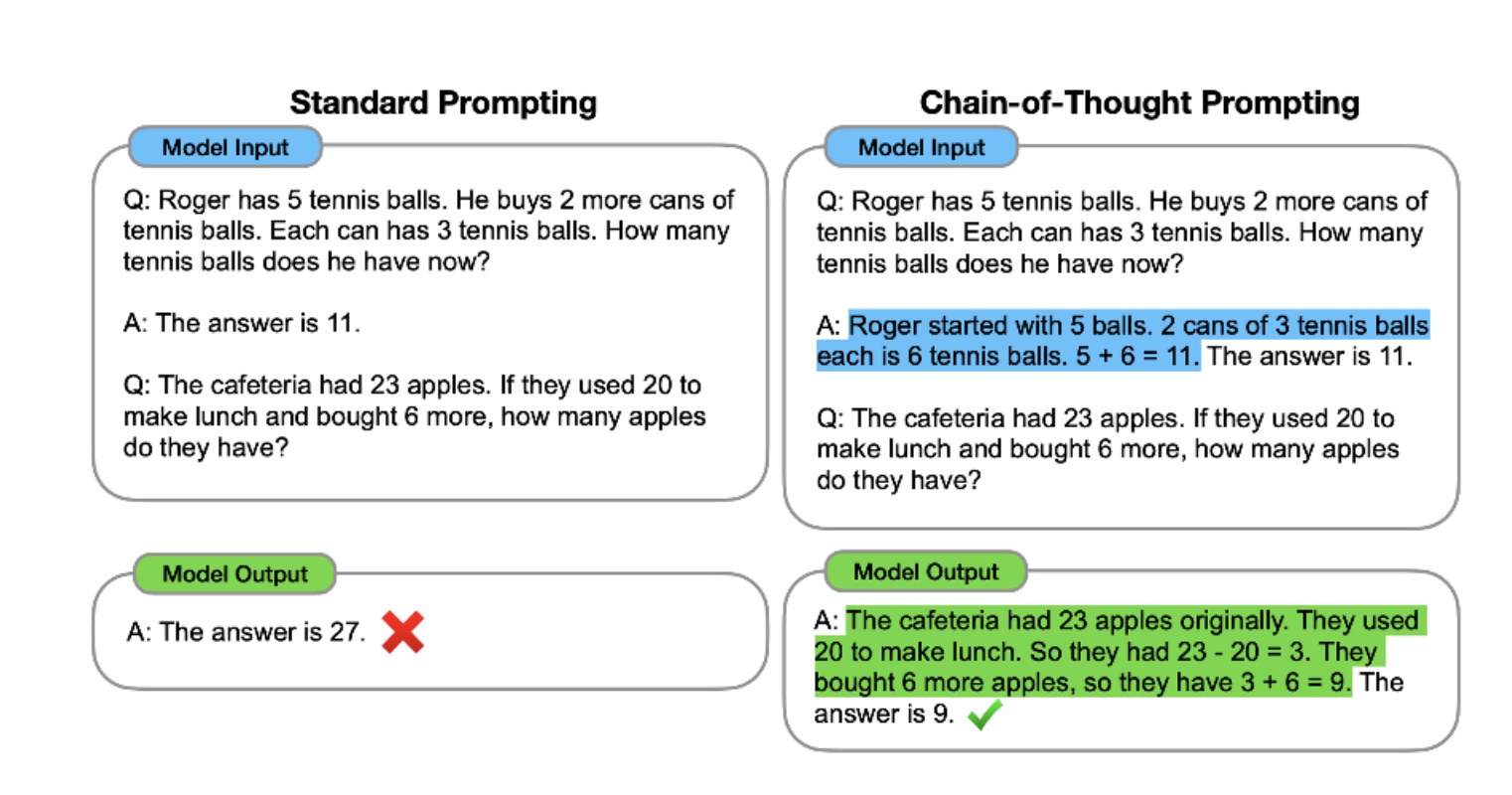
思维链提示(Chain-of-Thought Prompting)
ReAct框架
ReAct实际上是两个单词的缩写:Reasoning+ Acting,也就是推理+行动。

大模型为了完成一个大目标,需要不断地做一些任务。
每个任务都会经历思考(Thought)、行动(Action)、观察(Observation)三个阶段。
- 思考,决定了下一步的行动。
- 行动是完成了一个具体的动作。
- 观察,则是对行动结果进行评估,决定是否要结束这个处理过程。
流式应答
流式应答的出现主要是为了解决大模型生成文本比较慢的问题。
- 如果等大模型把所有内容生成一次性返回,等待的时间会非常⻓。
对于聊天的场景,这会让本已很⻓的等待时间会显得更加漫⻓。
大模型的核心工作就是一次添加一个Token。
- 我们不用等所有内容生成完毕,已经确定生成出来的内容可以先推送给用户。
OpenAI 在这个问题上却选择了SSE 这种技术。
OpenAI之所以选择 SSE,而非WebSocket:
是因为 SSE 的技术特点刚好可以契合流式应答的需求。
客户端与大模型的交互是一次性的,每产生一个Token,服务端就可以给客户端推送一次。
当生成内容结束时,断掉连接,无需考虑客户端的存活情况。
如果采用WebSocket的话,服务端就需要维护连接,像 OpenAI 这样的服务体量,维护连接就会造成很大的服务器压力。
- 而且,在生成内容场景下,也没有向服务端进一步发送内容。
- WebSocket的双向通信在这里也是多余的。