支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
机器学习就是从数据中发现规律
机器学习,就是在已知数据集的基础上。
通过反复的计算,选择最贴切的函数(function)去描述数据集中自变量x, x, x, …, x和因变量y之间的关系。
如果机器通过所谓的训练(training)找到了一个函数。
- 对于已有的1000组钻石数据,它都能够根据钻石的各种特征,大致推断出其价格。
那么,再给另一批同类钻石的大小、重量、颜色、密度等数据,就很有希望用同样的函数(模型)推断出这另一批钻石的价格。
此时,已有的1000组有价格的钻石数据,就叫作训练数据集(training dataset)。
另一批钻石数据,就叫作测试数据集(test dataset)。
通过机器学习模型不仅可以推测孩子身高和钻石价格,还可以实现影片票房预测、人脸识别。
机器学习就是从数据中发现关系,归纳成函数,以实现从A到B的推断。
机器学习的另外一个特质是从错误中学习:
机器学习的训练、建模的过程和人类的这个试错式学习过程有些相似。
机器找到一个函数去拟合(fit)它要解决的问题。
如果错误比较严重,它就放弃,再找到一个函数。
如果错误还是比较严重,就再找,一直到找到相对最为合适的函数为止,此时犯错误的概率最小。
这个寻找的过程,绝大多数情况不是在人类的指导下进行的,而是机器通过机器学习算法自己摸索出来的。
机器学习的类别
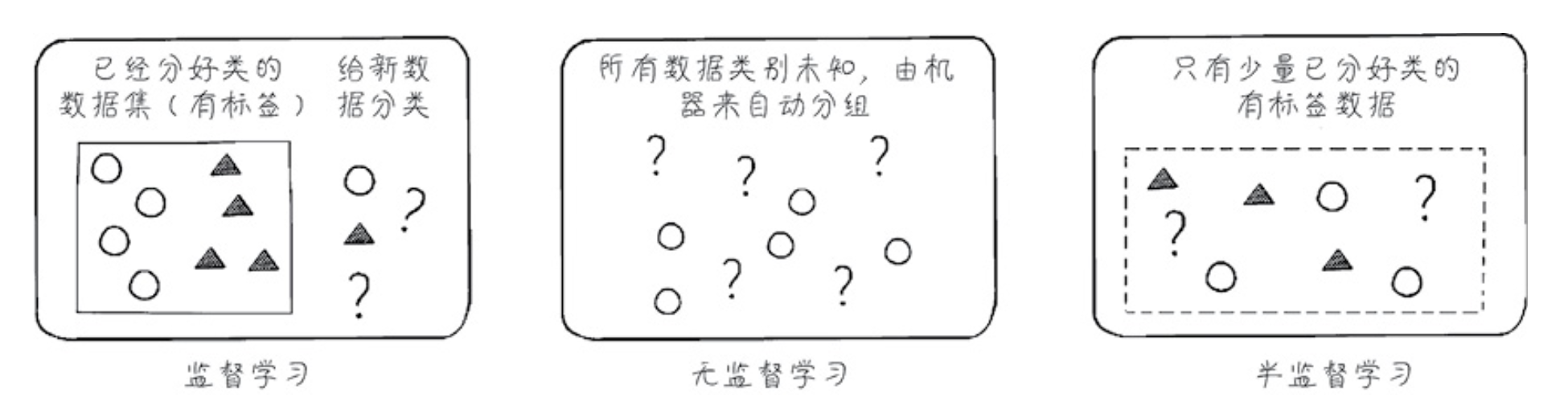
最常⻅的分类为:
- 监督学习(supervised learning)、无监督学习(unsupervised learning)。
- 半监督学习(semi-supervised learning)。
监督学习的训练需要标签数据,而无监督学习不需要标签数据,半监督学习介于两者之间。
使用一部分有标签数据,如下图所示。
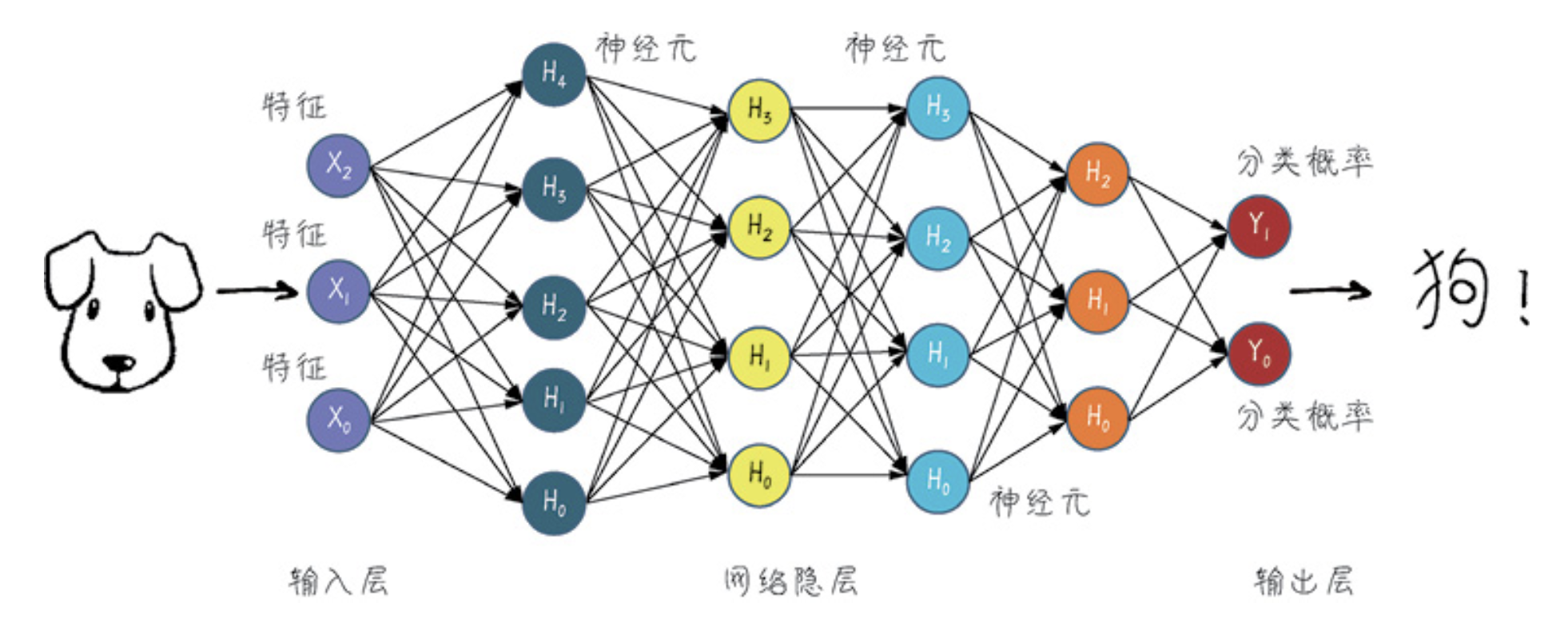
机器学习的重要分支—深度学习
层数较多、结构比较复杂的神经网络的机器学习技术叫作深度学习。
各种深度学习模型:
- 如卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network,RNN)。
在计算机视觉、自然语言处理(Natural Language Processing,NLP)、音频识别等应用中都得到了极好的效果。
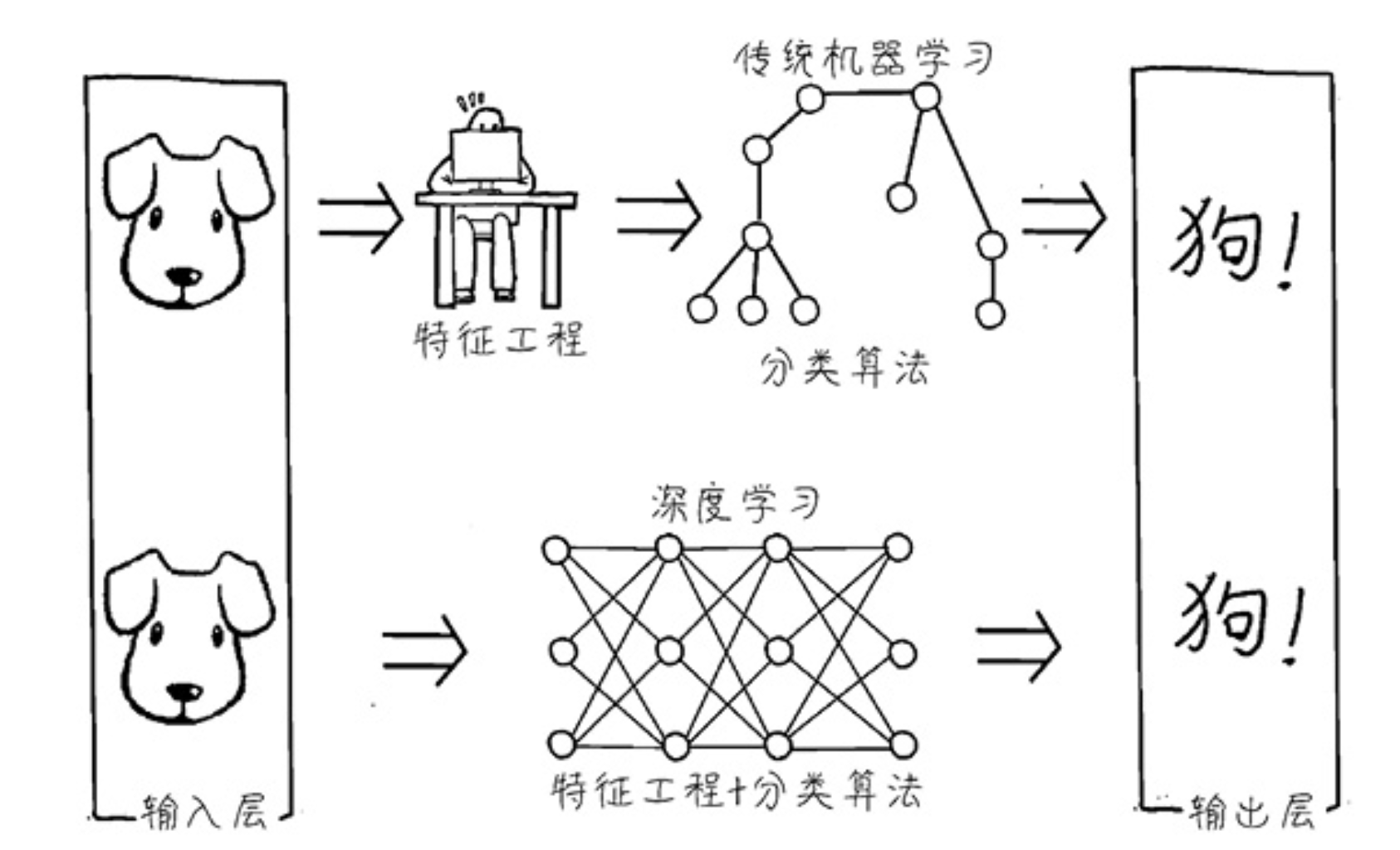
深度学习的另一大好处是对数据特征的要求降低:
自动地实现非结构化数据的结构化,无须手工获取特征,减少特征工程(feature engineering)。
- 特征工程是指对数据特征的整理和优化工作,让它们更易于被机器所学习。
在深度学习出现之前,对图像、视频、音频等数据做特征工程是非常烦琐的任务。
机器学习新热点—强化学习
强化学习(reinforcement learning)研究的目标是智能体(agent)如何基于环境而做出行动反应,以取得最大化的累积奖励。
智能体通过所得到的奖励(或惩罚)、环境反馈回来的状态以及动作与环境互动。
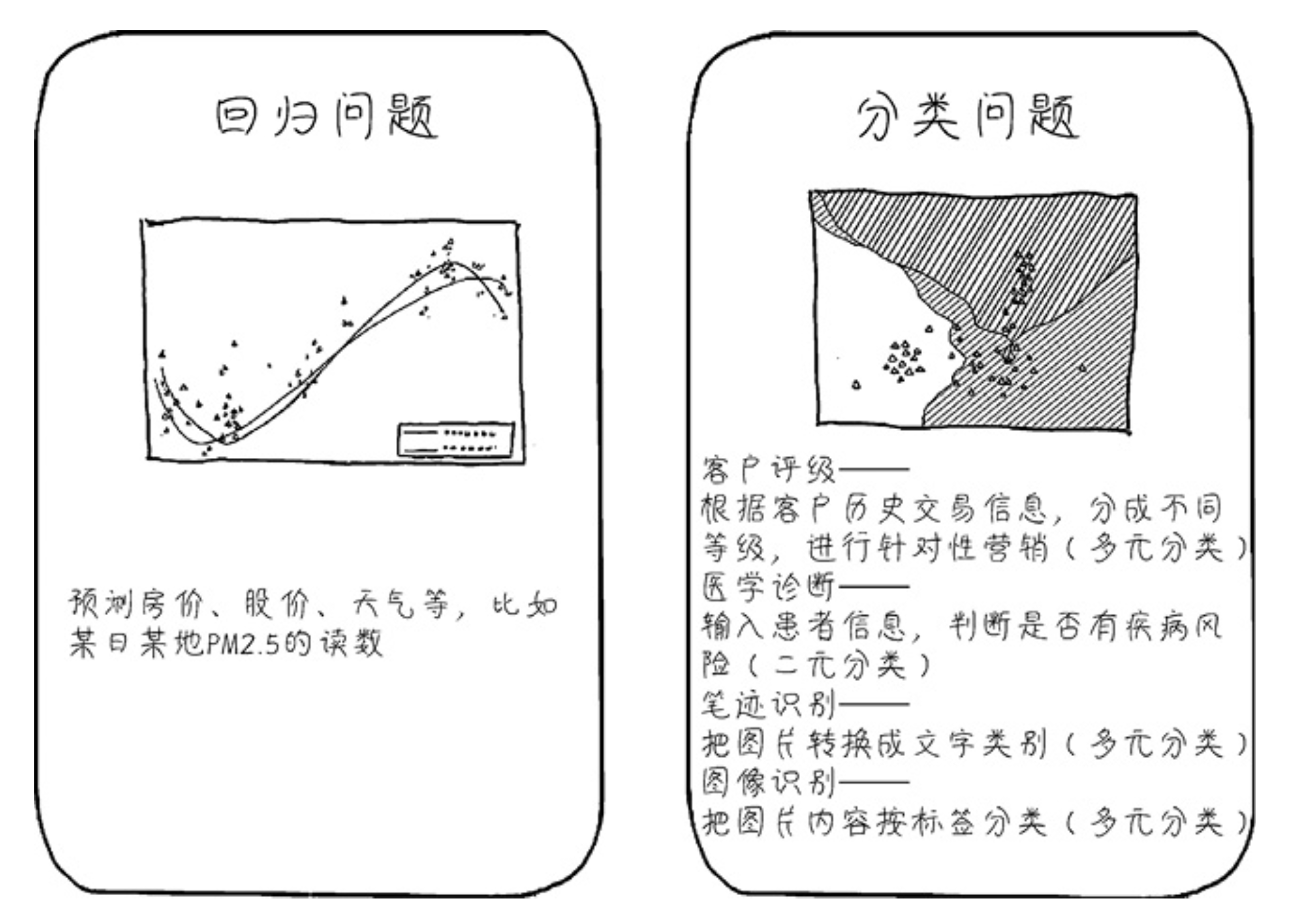
机器学习的两大应用场景—回归与分类
回归问题通常用来预测一个值,其标签的值是连续的。
- 例如,预测房价、未来的天气等任何连续性的走势、数值。
比较常⻅的回归算法是线性回归(linear regression)算法以及深度学习中的神经网络等。
分类问题是将事物标记一个类别标签:
结果为离散值,也就是类别中的一个选项,例如,判断一幅图片上的动物是一只猫还是一只狗。